

.png)
Introduction
In November 2025, Kikoff launched Fynn - an AI-powered Credit Coach built to help users understand credit and make better financial decisions.
Like any experimental launch, we rolled Fynn out in stages - starting with a small cohort, then expanding exposure to 10%, 25%, and 50% as we saw strong user interest and consistently high CSAT.
Over the past few months, Fynn has moved from a beta cohort to every Kikoff user, reaching 100% scale.
That rollout depended on two changes. First, we reorganized Fynn’s expertise around composable skills instead of larger domain-specific prompt blocks (agents). Second, we built an evaluation loop that gives us confidence before changes reach our users.
Neither change would have been enough on its own. Together, they made Fynn easier to improve and safer to ship.
Why The Beta Needed To Change
Early Fynn worked well enough to prove the product was useful. It could answer questions about credit building, rent reporting, debt settlement, secured cards, and other Kikoff topics. But as we prepared to make it available to everyone, a few limits became clear.
Real customer questions rarely fit cleanly into one category. Someone might ask about bill reporting and how that affects their credit score. Or they might ask about payment history, credit utilization, and their secured card in the same message. Some users also naturally put several related questions into a numbered list instead of sending them as separate messages. Fynn needed to bring together the right context without treating those as separate conversations.
The old setup also made iteration harder than it needed to be. Shared guidance was repeated across too many places, and improving one area often meant carefully checking that the same idea had been updated elsewhere. That slowed down the prompt iteration an AI product needs to keep getting better.
Most importantly, we needed a better way to know whether a change was actually helping. Trying a few examples manually is fine during early development, but it is not enough when the assistant is about to become a default experience for every user.
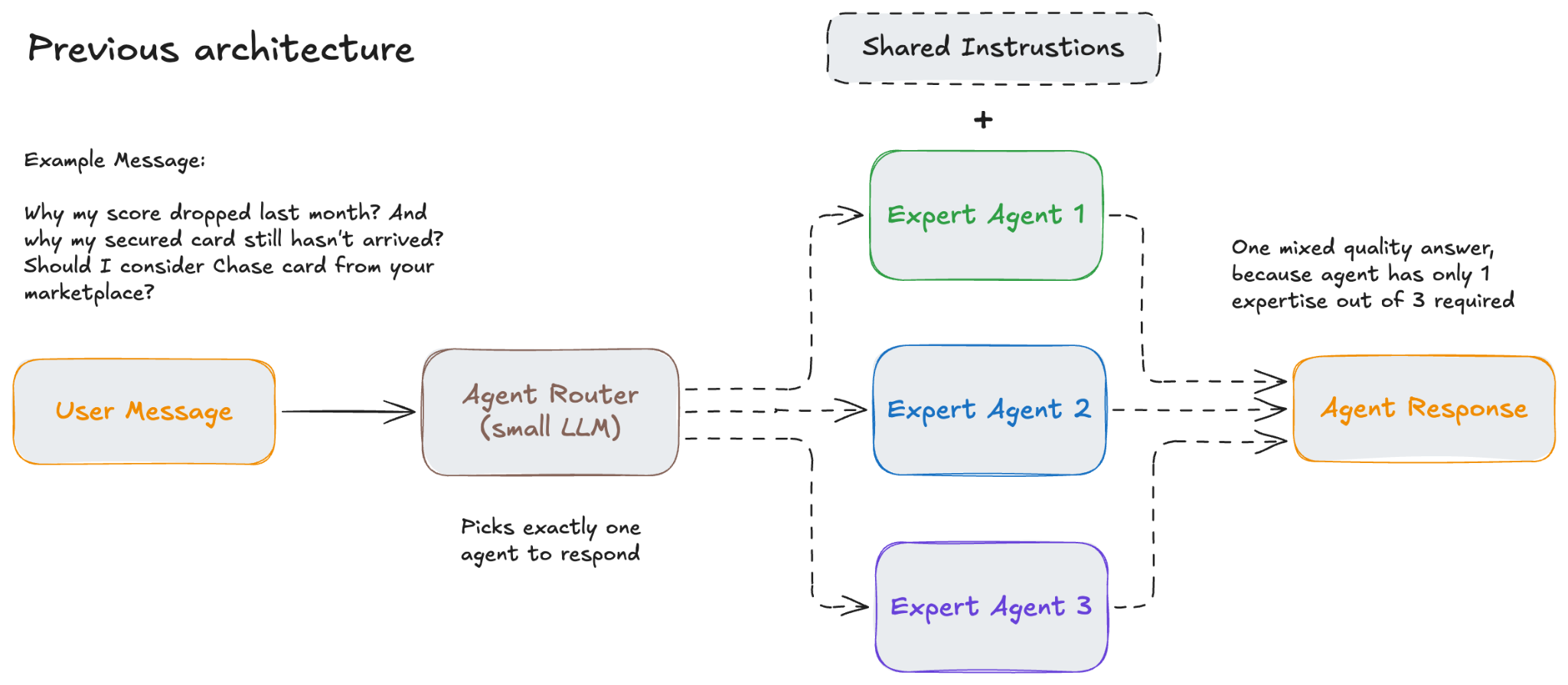
Organizing Fynn Around Skills
We moved Fynn’s expertise into a library of smaller skills.
The idea came from a place we already trusted: coding agents. We had been using Claude Code skills to give agents the right context for a task without stuffing every possible instruction into the context window. That pattern mapped surprisingly well to Fynn. A user asking about debt negotiation does not need every detail about every Kikoff product, but a user asking about debt negotiation and secured cards should not be forced into one lane either. Skills gave us a way to load the right expertise at the right time.
Some skills define Fynn’s core behavior: how it should communicate, what it should avoid, and how it should help users understand credit. Others focus on specific topics, like credit utilization, rent reporting, or debt settlement. A skill can also define a communication style, a guardrail, or another boundary Fynn needs in order to stay accurate and safe.
For each conversation, Fynn can use the skills that fit the user’s question. That means one assistant can answer a question that crosses several domains without losing its voice or forcing the user into an internal category.
This changed how we work on Fynn. A skill is small enough to improve directly. If we want to make Fynn better at explaining credit utilization, we can focus on that skill instead of editing a much larger prompt.
A skill is also easier to test. We can build evaluations around a specific behavior and see whether a proposed change improves it, hurts it, or has no meaningful effect.
And skills make experimentation cleaner. We can test a new explanation style, a sharper guardrail, or a domain-specific instruction without cloning the entire assistant experience.
The product stays simple for users. There is still one Fynn: one place to ask questions, one voice, one experience. The composition happens behind the scenes.
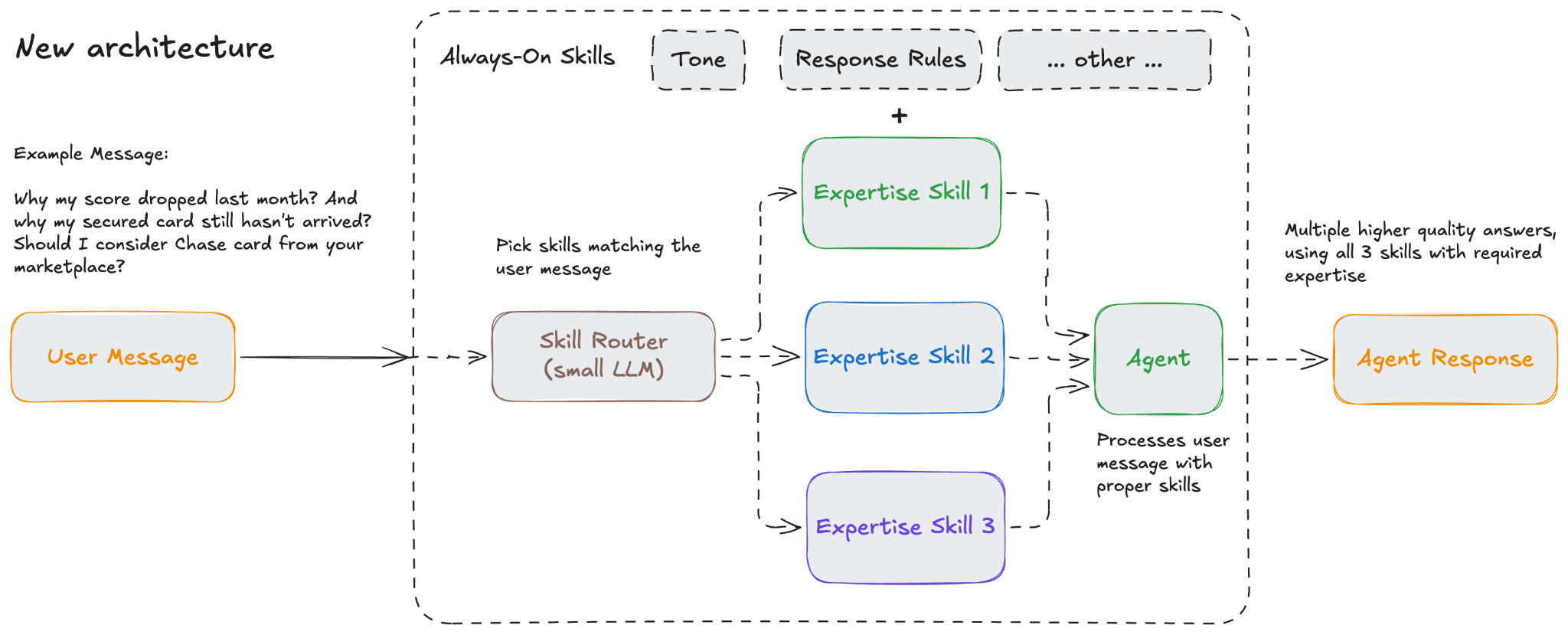
Building An Evaluation Loop We Trust
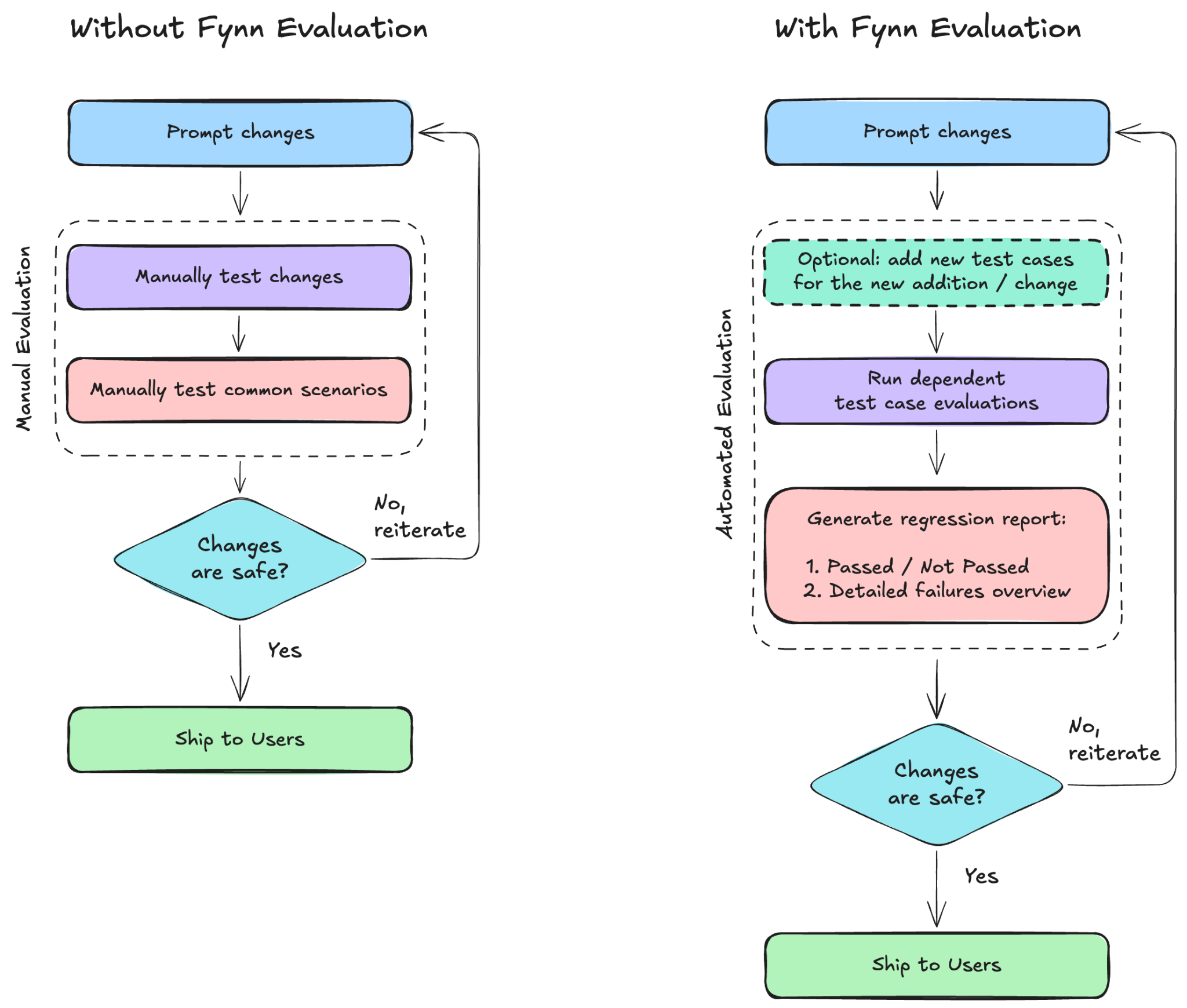
Prompt changes are product changes. We needed a way to review them with the same seriousness we bring to code.
Our prompts had been versioned from day one, much like code. What they were missing was the prompt equivalent of CI. Code changes do not go straight to production just because they look right in review, and prompt changes should not either. Regression reports became our sanity check before shipping: not perfect proof, but enough signal to catch obvious failures, compare drafts, and make prompt edits feel like reviewable engineering changes.
So we built an evaluation loop around realistic test scenarios, automated grading, and regression reports.
The first piece is synthetic users. These are test personas with realistic financial profiles and product states, but no real customer data. They let us test how Fynn behaves for users in different situations: someone new to credit, someone working through negative marks, someone managing payments, someone using Kikoff products in different ways.
The second piece is evaluation datasets. Each dataset focuses on a behavior we care about, such as answering a secured card question correctly, explaining a credit concept clearly, or using available context appropriately.
The third piece is automated scoring. Some checks are objective, like whether Fynn used the right available information. Others need judgment, so we use model-based graders that compare Fynn’s answer against an expected answer and explain the score.
The fourth piece is making evaluations part of the editing workflow. When a skill changes, the relevant evals run against the proposed version. The result is a regression report that shows whether the change moved quality in the right direction before it ships.
The first realistic datasets paid for themselves almost immediately. As soon as we ran Fynn against near-real scenarios, we found dozens of small deviations: answers that were mostly right but too vague, explanations that skipped a detail a real user would care about, and cases where the assistant used context in a defensible but suboptimal way. None of them were dramatic on their own. Together, they were exactly the kind of low-hanging quality work that is hard to see without a repeatable eval set.
That loop has already changed how we work. Instead of debating prompt edits from intuition alone, we can look at examples, scores, and failures. The goal is not to pretend evals are perfect. The goal is to make every change more observable than it was before.
Why Both Changes Had To Ship Together
Skills made Fynn easier to change. Evals made those changes safer.
Either one on its own would have been incomplete. With skills but no evals, we would have had a faster way to edit Fynn without enough confidence that those edits were helping. With evals but no skills, we would have had better visibility into problems, but fewer clean ways to fix them without touching too much at once.
Together, they created a much better development loop. A skill edit becomes a focused change. The relevant evals run against it. The regression report shows where behavior improved, where it regressed, and which examples deserve a closer look.
It also made experimentation feel lighter. Once Fynn’s behavior was broken into smaller pieces, new ideas became easier to try: different tones for different user cohorts, response structures for people who prefer step-by-step guidance, narrower A/B tests around a single behavior, and internal diagnostic skills that help us understand what Fynn is doing.
That was the real shift. Fynn stopped feeling like one large assistant we had to be careful around and started feeling like a product we could keep improving in controlled, reviewable steps.
Getting To 100%
There was no single moment where Fynn suddenly became ready for everyone. It was more gradual than that. The rollout started to feel real when prompt changes stopped feeling like bets and started feeling like reviewable product changes.
We were no longer just hoping the assistant would behave well at a larger scale. We had a system for changing it, testing it, and seeing the impact before users did.
Defaulting Fynn to every Kikoff user was not just a launch decision. It was the result of making Fynn easier to improve and safer to change.
If this kind of work sounds exciting to you — building AI products that are thoughtful, testable, and designed to actually help people — we'd love to have you on the team. Check out our open roles at kikoff.com/careers.
About the Writer

Almir Davletov is a Staff Software Engineer with strong AI expertise. He began teaching himself to code in 7th grade and went on to study at Kazan Federal University in Russia. He built his career from freelancing and working at the international IT company Provectus, eventually making his way to California where he joined LeetCode as a lead software engineer. At LeetCode, he has developed AI-powered solutions including a plagiarism detection system for coding competitions and a data mining platform using large language models. He is also a senior member of the IEEE and has published research on machine learning integration in commercial settings.
















